GPT-5.3-Codex 深度评测:25% 速度提升,代码智能体新标杆
分类: 各厂语言模型 |发布于: 2/7/2026 |最后更新: 2/7/2026
⚡ GPT-5.3-Codex 深度评测
25% 速度提升,三合一能力整合,代码智能体新标杆
2026年2月5日,OpenAI 发布了 GPT-5.3-Codex,这是迄今为止最强大的代码智能体模型。它将 GPT-5.2-Codex 的编程能力、GPT-5.2 的推理能力整合在一起,同时实现了 25% 的速度提升。
🎯 核心亮点速览
- 三合一整合:GPT-5.2-Codex 编程 + GPT-5.2 推理 + 25% 速度提升
- 超长任务支持:可运行超过 24 小时的长时间任务
- 数百万 Token 处理:支持超大代码库分析
- High 安全级别:首个获此评级的模型
🚀 三大核心能力
💻 前沿编程能力
继承 GPT-5.2-Codex 的所有编程能力,在代码生成、调试、重构方面保持顶尖水准。
🧠 强大推理能力
整合 GPT-5.2 的推理和专业知识,能够理解复杂业务逻辑和技术架构。
⚡ 25% 速度提升
整体响应速度提升 25%,大幅改善开发者体验,减少等待时间。
🎯 智能意图理解
模糊需求也能得到合理实现,减少来回沟通次数,提高开发效率。
📊 基准测试表现
SWE-Bench Pro 软件工程
评估模型解决真实软件工程问题的能力,是衡量代码智能体实力的核心指标。
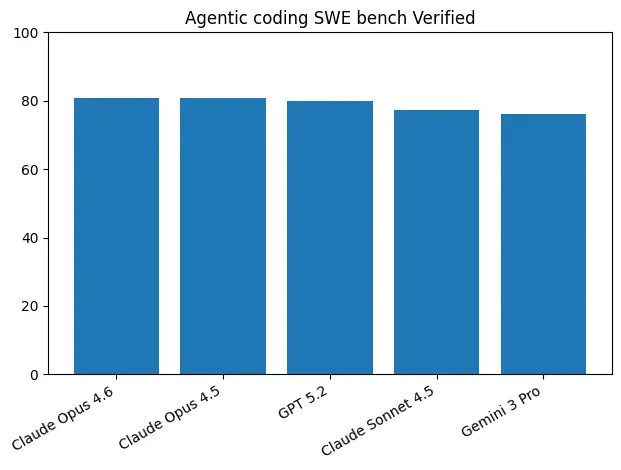
🏆
GPT-5.3-Codex 在 SWE-Bench Pro 上达到行业最高水平,展现出卓越的代码理解和问题解决能力。
Terminal-Bench 2.0 终端操作
评估模型在命令行环境中执行开发操作的能力。
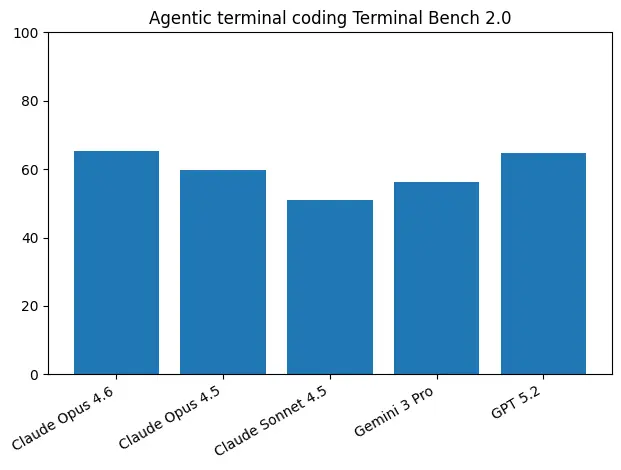
GPT-5.3-Codex 得分 64.7%,在终端操作方面表现出色,与 Claude Opus 4.6 (65.4%) 接近。
🔧 工程痛点优化
📁 代码库一致性
更好地理解和维护大型代码库的风格一致性,减少代码审查负担。
🔍 深度差异对比
智能分析代码变更,提供更有价值的 diff 解释和影响分析。
🔄 修复 Lint 循环
解决了之前版本中 lint 修复可能陷入循环的问题。
🐛 清晰 Bug 解释
发现 bug 时提供更清晰的解释和修复建议,加速调试过程。
🔒 安全性突破
⚠️ 首个 High 安全级别模型
GPT-5.3-Codex 是首个被分类为 High 安全级别 的 AI 模型。OpenAI 承诺提供 1000万美元网络防御信用额度,用于帮助企业应对潜在的安全风险。
⚔️ 与 Claude Opus 4.6 对比
| 特性 | GPT-5.3-Codex | Claude Opus 4.6 |
|---|---|---|
| 核心理念 | 交互式协作开发 | 自主深度思考 |
| 特色功能 | 25% 速度提升 | Agent Teams 多智能体 |
| 上下文窗口 | 128K (标准) | 1M Token |
| Terminal-Bench 2.0 | 64.7% | 65.4% |
| SWE-Bench | 80.0% | 80.8% |
| 安全级别 | High | Standard |
| 适合场景 | 快速迭代、交互式开发 | 复杂研究、长时间任务 |
📋 点击查看详细基准数据
| 基准测试 | GPT-5.3-Codex | GPT-5.2 | Opus 4.6 | Gemini 3 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 64.7% | 62.1% | 65.4% | 56.2% |
| SWE-bench Verified | 80.0% | 78.5% | 80.8% | 76.2% |
| τ2-bench Retail | 82.0% | 80.1% | 91.9% | 85.3% |
| GPQA Diamond | 93.2% | 91.8% | 91.3% | 91.9% |
| Finance Agent | 56.6% | 54.2% | 60.7% | 44.1% |
💡 选择建议
🎯 GPT-5.3-Codex 适合
- 快速迭代开发:25% 速度提升让交互更流畅
- 企业级安全需求:High 安全级别 + 网络防御信用
- 日常编程任务:代码生成、调试、重构
- 团队协作开发:交互式协作模式
💡
选择建议:如果你需要快速响应和企业级安全,选 GPT-5.3-Codex;如果你需要处理超长上下文或复杂研究任务,选 Claude Opus 4.6。
本文由加装AI助手整理发布 | 数据来源:OpenAI 官方 + 第三方评测 2026年2月