Claude Opus 4.6 重磅发布:Anthropic 最强模型全面领先,编程与智能体能力再创新高
🚀 Claude Opus 4.6 重磅发布
Anthropic 最强模型全面升级,编程、智能体、长上下文能力再创新高
2026年2月5日,Anthropic 正式发布了 Claude Opus 4.6,这是其迄今为止最强大的 AI 模型。新模型在智能体编程、计算机操作、工具使用、搜索和金融分析等多个领域均达到行业领先水平,部分指标大幅超越竞争对手。
- SWE-bench Verified 80.8%:与 Opus 4.5 持平,超越 GPT-5.2 的 80.0%
- Terminal-Bench 2.0 65.4%:智能体编程评测行业最高分
- 1M Token 上下文窗口:首个支持百万 Token 的 Opus 级模型
- 128K 输出 Token:支持超长输出,无需拆分请求
- Agent Teams:Claude Code 新增多智能体协作功能
📊 核心评测数据
🔧 SWE-bench Verified(软件工程能力)
SWE-bench Verified 是评估 AI 模型解决真实 GitHub Issue 能力的权威基准。Claude Opus 4.6 在该评测中取得 80.8% 的成绩。
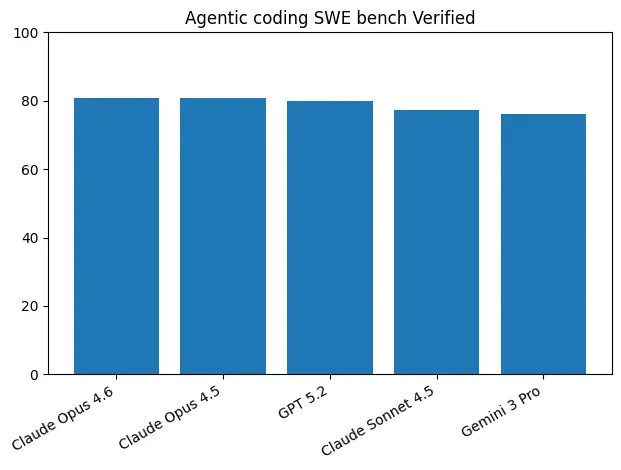
这一成绩与 Opus 4.5 的 80.9% 基本持平,略高于 GPT-5.2 的 80.0%,显著领先于 Sonnet 4.5(77.2%)和 Gemini 3 Pro(76.2%)。
💻 Terminal-Bench 2.0(智能体编程)
Terminal-Bench 2.0 评估模型在真实终端环境中执行复杂编程任务的能力。Opus 4.6 以 65.4% 的成绩创下行业新高。
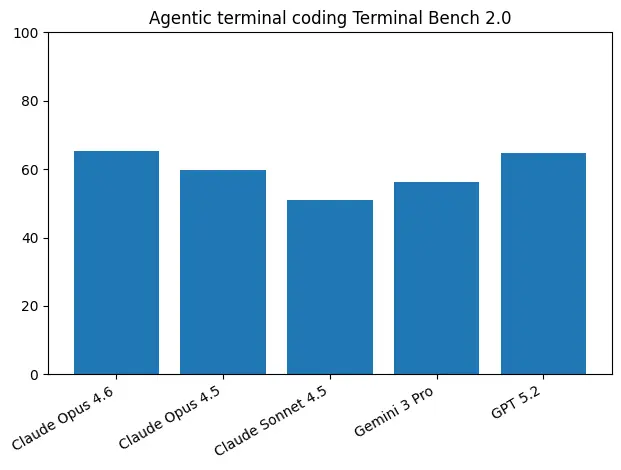
这一成绩展示了 Opus 4.6 在长时间自主编程任务中的卓越表现。
🖥️ OSWorld(计算机操作)
OSWorld 评估模型操作计算机完成复杂任务的能力。Opus 4.6 取得 72.7% 的成绩。
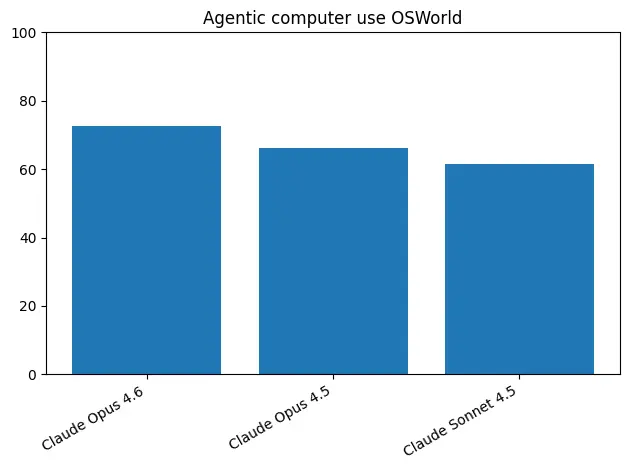
📈 模型对比
| 评测项目 | Claude Opus 4.6 | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 80.9% | 80.0% | 76.2% |
| Terminal-Bench 2.0 | 65.4% | - | - | - |
| OSWorld | 72.7% | - | - | - |
| Humanity's Last Exam | 行业领先 | - | - | - |
| BrowseComp(搜索) | 行业最高 | - | - | - |
| 上下文窗口 | 1M tokens | 200K | 128K | 1M |
| 最大输出 | 128K tokens | - | - | - |
🆕 重要新功能
🤖 Agent Teams(智能体团队)
Claude Code 新增多智能体协作功能,可同时启动多个智能体并行工作,自主协调完成复杂任务,特别适合代码审查等需要分工的场景。
🧠 Adaptive Thinking(自适应思考)
模型可根据任务复杂度自动决定是否启用深度推理,开发者可通过 effort 参数(low/medium/high/max)精细控制。
📦 Context Compaction(上下文压缩)
自动总结和压缩旧上下文,让 Claude 能执行更长时间的任务而不会触及上下文限制。
📊 Claude in Excel/PowerPoint
Excel 集成大幅升级,新增 PowerPoint 支持(研究预览),可直接在办公软件中使用 AI 能力。
🔒 安全性提升
Anthropic 强调 Opus 4.6 在能力提升的同时保持了出色的安全性:
- 在自动化行为审计中,错误对齐行为率与 Opus 4.5 持平(业界最低)
- 过度拒绝率(误拒良性请求)为近期 Claude 模型中最低
- 新增 6 个网络安全探测器,防止模型被滥用
- 运用可解释性技术深入理解模型行为
📋 点击查看早期合作伙伴评价
- GitHub:"在复杂的多步骤编程工作中表现出色,尤其是需要规划和工具调用的智能体工作流。"
- Cursor:"在长时间运行任务上达到新前沿,代码审查能力非常出色。"
- Replit:"智能体规划能力的巨大飞跃,能将复杂任务分解为独立子任务并行执行。"
- Notion:"感觉不像工具,更像一个有能力的协作者。"
本文由加装AI助手整理发布 | 数据来源:Anthropic、Vellum AI、Artificial Analysis